
No Ray Summit deste ano, estamos felizes em apresentar o stack de infraestrutura que estamos criando com a IBM Research, que inclui o Ray e o CodeFlare para cargas de trabalho distribuídas de inteligência artificial generativa. As tecnologias são introduzidas em comunidades open source, como o Open Data Hub, e amadurecem para se tornarem parte do Red Hat OpenShift AI, que também está presente no IBM watsonx.ai e nos modelos base da IBM usados pelo Red Hat Ansible Automation Platform. O Red Hat OpenShift AI reúne um conjunto avançado de ferramentas e tecnologias projetadas para tornar o processo de ajuste fino e disponibilização de modelos base fluido, escalável e eficiente. A plataforma oferece essas ferramentas para ajustar, treinar e implantar modelos de forma consistente, seja no local ou na nuvem. Nosso trabalho mais recente oferece várias opções para ajustar e fornecer modelos base, oferecendo aos profissionais de ciência de dados e MLOps recursos, como acesso em tempo real a funcionalidades de cluster ou a capacidade de programar cargas de trabalho para processamento em lote.
Neste blog, você aprenderá como fazer o ajuste fino e implantar de maneira simplificada um modelo HuggingFace GPT-2 composto por 137 milhões de parâmetros em um conjunto de dados WikiText usando o Red Hat OpenShift AI. O ajuste fino será feito usando o stack Distributed Workloads com o KubeRay subjacente para paralelização e o stack KServe/Caikit/TGIS para implantação e monitoramento do nosso modelo base GPT-2 ajustado.
O stack Distributed Workloads consiste em dois componentes principais:
- KubeRay: operador Kubernetes para implantação e gerenciamento de clusters Ray remotos executando cargas de trabalho de computação distribuídas; e
CodeFlare: operador do Kubernetes que implanta e gerencia o ciclo de vida de três componentes:
- CodeFlare-SDK: ferramenta para definir e controlar trabalhos e infraestrutura de computação distribuída remota. O operador CodeFlare implanta um notebook com o CodeFlare-SDK.
- Multi-Cluster Application Dispatcher (MCAD): controlador Kubernetes para gerenciar trabalhos em lote em um ambiente com um ou vários clusters
- InstaScale: escala sob demanda de recursos agregados em qualquer tipo do OpenShift com configuração MachineSets (autogerenciado ou gerenciado: Red Hat OpenShift on AWS/Open Data Hub).
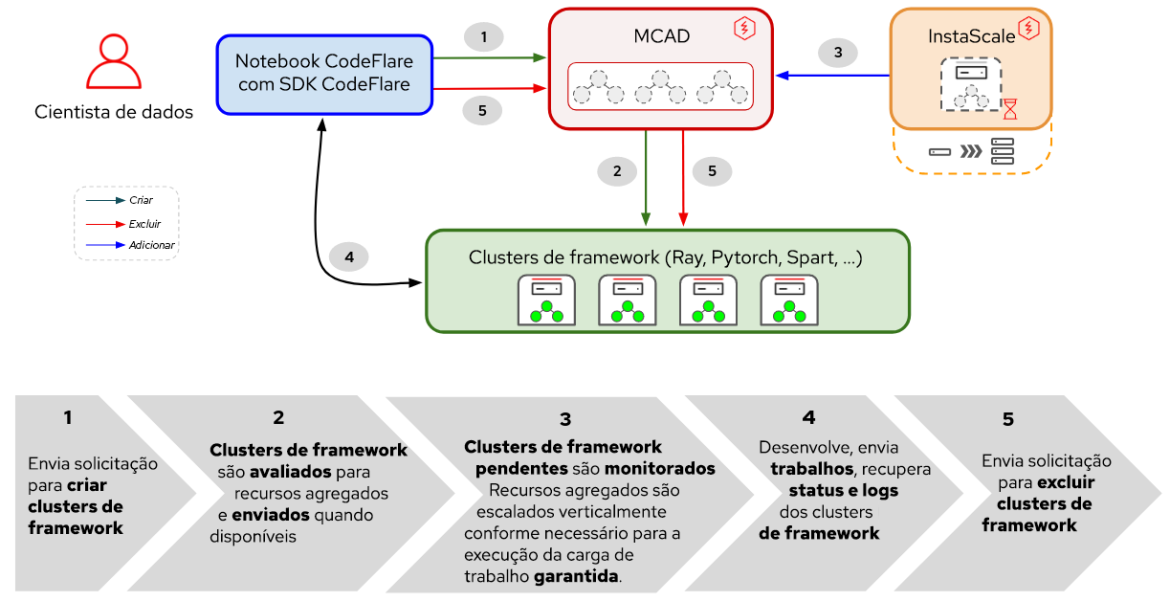

Figura 1. Interações entre componentes e fluxo de trabalho do usuário na Distributed Workloads.
Conforme mostrado na Figura 1, no Red Hat OpenShift AI, o ajuste do seu modelo base começará com o CodeFlare, um framework dinâmico que otimiza e simplifica a criação, o treinamento e o refinamento de modelos. Além disso, você aproveitará o poder do Ray, um framework de computação distribuído, usando o KubeRay para distribuir com eficiência seus esforços de ajuste fino, reduzindo significativamente o tempo necessário para alcançar o desempenho ideal do modelo. Depois de definir sua carga de trabalho com ajuste fino, o MCAD colocará sua carga de trabalho Ray em fila até que os requisitos de recursos sejam atendidos e, em seguida, criará o cluster do Ray assim que houver uma garantia de que todos os seus pods podem ser agendados.
Para a veiculação, o stack KServe/Caikit/TGIS é composto por:
- KServe: definição de recurso personalizado do Kubernetes para modelos de serviço de produção que lida com o ciclo de vida da implantação de modelos
- Servidor de inferência de geração de texto (TGIS): back-end/servidor de serviço que carrega os modelos e fornece o mecanismo de inferência
- Caikit: kit de ferramentas/runtime de IA que lida com o ciclo de vida do processo de TGIS, fornece endpoints de inferência e módulos que lidam com diferentes tipos de modelos
- OpenShift Serverless (operador de pré-requisito): é baseado no projeto open source Knative, que permite aos desenvolvedores criar e implantar aplicações serverless e orientadas a eventos de nível empresarial
OpenShift Service Mesh (operador de pré-requisito): é baseado no projeto open source Istio, que fornece uma plataforma para insights comportamentais e controle operacional sobre microsserviços em rede em uma service mesh.

Figura 2. Interações entre os componentes e o fluxo de trabalho do usuário no stack KServe/Caikit/TGIS.
Depois de fazer o ajuste fino no modelo, você deverá implementá-lo com o runtime e o back-end do serviço do Caikit/TGIS, simplificando e otimizando a escala e a manutenção do seu modelo usando o KServe, que fornece uma infraestrutura de serviço confiável e avançada. Em segundo plano, o Red Hat OpenShift Serverless (Knative) provisionará a implantação serverless do nosso modelo, e o Red Hat OpenShift Service Mesh (Istio) cuidará de todos os fluxos de rede e tráfego (veja a Figura 2).
Configuração do ambiente
Esta demonstração pressupõe que você tem um cluster do OpenShift com o operador Red Hat OpenShift AI instalado ou adicionado como um complemento. A demonstração também pode ser executada com o Open Data Hub como uma plataforma subjacente.
Para fazer o ajuste fino do seu modelo, você precisará instalar o operador da comunidade CodeFlare disponível no OperatorHub. O operador CodeFlare instala o MCAD, o InstaScale, o operador KubeRay e a imagem de notebook CodeFlare com pacotes como codeflare-sdk, pytorch e turbinex incluídos. Se você usar GPUs, os operadores NVIDIA GPU e Node Feature Discovery também precisarão ser instalados.
Para o serviço do modelo, basta executar este script, e ele instalará todos os operadores de pré-requisito e toda o stack KServe/Caikit/TGIS. Defina TARGET_OPERATOR como rhods
Embora as instruções de instalação dos stacks Distributed Workloads e KServe/Caikit/TGIS sejam mais ou menos manuais aqui, elas estarão disponíveis e terão suporte no Red Hat OpenShift AI em breve.
Ajuste fino de um modelo de LLM
Para começar, inicie o notebook CodeFlare no dashboard do Red Hat OpenShift AI (veja a Figura 3) e clone o repositório de demonstração, que inclui o notebook e outros arquivos necessários para esta demonstração.

Figura 3. Imagem do notebook CodeFlare exibida no dashboard do OpenShift Data Science.
No início, você deve definir os parâmetros para o tipo de cluster que deseja (ClusterConfiguration), como o nome do cluster, o namespace no qual implantar, os recursos necessários de CPU, GPU e memória, tipos de máquina e se você gostaria de aproveitar os recursos de escalabilidade automática do InstaScale. Se você estiver trabalhando em um ambiente on-premise, poderá ignorar o machine_types e definir instascale=False . Depois, o objeto de cluster é criado e enviado ao MCAD para girar o cluster do Ray.
Quando o cluster do Ray estiver pronto e você puder ver os detalhes do cluster do Ray a partir do comando cluster.details() no notebook, será possível definir seu trabalho de ajuste fino fornecendo um nome, o script a ser executado, argumentos (se houver) e a lista de bibliotecas necessárias e, em seguida, enviar ao cluster do Ray que você acabou de iniciar. A lista de argumentos especifica o modelo GPT-2 a ser usado e o conjunto de dados WIkiText com o qual fazer o ajuste fino do modelo. A parte interessante do CodeFlare SDK é que você pode rastrear convenientemente o status, os logs e outras informações por meio da interface de linha de comando (CLI) ou visualizá-las em um dashboard do Ray.
Quando o processo de ajuste fino do modelo for concluído, você poderá ver que a saída de job.status() muda para SUCCEEDED e os logs no dashboard do Ray mostram a conclusão (veja a Figura 4). Com um nó de trabalho Ray executado na GPU NVIDIA T4 com 2 CPUs e 8 GB de memória, o ajuste fino do modelo GPT2 levou aproximadamente 45 minutos.

Figura 4. Os logs do dashboard do Ray mostram a conclusão do processo de ajuste fino do modelo.
Depois, você precisará criar um novo diretório no notebook, salvar o modelo lá e, em seguida, fazer o download dele para seu ambiente local para converter o modelo e fazer upload dele para um bucket MinIO. Observe que estamos usando um bucket MinIO nesta demonstração. No entanto, você pode optar por usar outro tipo de bucket S3, PVC ou qualquer outro tipo de armazenamento de sua preferência.
Como servir o modelo LLM
Agora que você fez o ajuste fino do seu modelo base, é hora de colocá-lo em prática. No mesmo notebook em que você ajustou seu modelo, é possível criar um novo namespace no qual você:
- Implanta o Caikit+TGIS Serving Runtime;
- Implanta a conexão de dados S3; e
- Implanta o serviço de inferência que aponta para seu modelo localizado em um bucket MinIO
Um runtime de serviço é uma definição de recurso personalizado designada para criar um ambiente para implantação e gerenciamento de modelos em produção. Ele cria os templates para pods que podem carregar e descarregar dinamicamente modelos de vários formatos sob demanda e expor um endpoint de serviço para inferência de solicitações. Você implantará o runtime de serviço, que ajustará a escala verticalmente dos pods do runtime assim que um serviço de inferência for detectado. A porta 8085 será usada para inferência.
Um serviço de inferência é um servidor que aceita dados de entrada, passa esses dados para o modelo, executa o modelo e retorna a saída de inferência. No InferenceService que você está implantando, é necessário especificar o runtime implantado anteriormente, habilitar a rota de pass-through para inferência de gRPC e apontar o servidor para seu bucket MinIO onde o modelo ajustado está localizado.
Depois de verificar se o serviço de inferência está pronto, realize uma chamada de inferência solicitando que o modelo conclua uma frase de sua escolha.
Pronto, você fez o ajuste fino de um grande modelo de linguagem GPT-2 com o stack Distributed Workloads e o veiculou com êxito o stack KServe/Caikit/TGIS no OpenShift AI.
A seguir
Gostaríamos de agradecer às comunidades do Open Data Hub e do Ray pelo apoio. Isso é apenas uma pequena amostra dos possíveis casos de uso de inteligência artificial e machine learning com o OpenShift AI. Se quiser mais informações sobre os recursos de stack do CodeFlare, confira o vídeo de demonstração que desenvolvemos e que aborda em mais detalhes as partes do CodeFlare SDK, KubeRay e MCAD desta demonstração.
Fique ligado, pois integraremos os operadores CodeFlare e KubeRay ao OpenShift Data Science muito em breve e desenvolveremos a IU para o stack KServe/Caikit/TGIS que foi recentemente lançado no OpenShift Data Science como uma funcionalidade de disponibilidade limitada.
Sobre o autor

Selbi Nuryyeva is a software engineer at Red Hat in the OpenShift AI team focusing on the Open Data Hub and Red Hat OpenShift Data Science products. In her current role, she is responsible for enabling and integrating the model serving capabilities. She previously worked on the Distributed Workloads with CodeFlare, MCAD and InstaScale and integration of the partner AI/ML services ecosystem. Selbi is originally from Turkmenistan and prior to Red Hat she graduated with a Computational Chemistry PhD degree from UCLA, where she simulated chemistry in solar panels.
Navegue por canal

Automação
Últimas novidades em automação de TI para empresas de tecnologia, equipes e ambientes

Inteligência artificial
Descubra as atualizações nas plataformas que proporcionam aos clientes executar suas cargas de trabalho de IA em qualquer ambiente

Nuvem híbrida aberta
Veja como construímos um futuro mais flexível com a nuvem híbrida

Segurança
Veja as últimas novidades sobre como reduzimos riscos em ambientes e tecnologias

Edge computing
Saiba quais são as atualizações nas plataformas que simplificam as operações na borda

Infraestrutura
Saiba o que há de mais recente na plataforma Linux empresarial líder mundial

Aplicações
Conheça nossas soluções desenvolvidas para ajudar você a superar os desafios mais complexos de aplicações

Programas originais
Veja as histórias divertidas de criadores e líderes em tecnologia empresarial
Produtos
- Red Hat Enterprise Linux
- Red Hat OpenShift
- Red Hat Ansible Automation Platform
- Red Hat Cloud Services
- Veja todos os produtos
Ferramentas
- Treinamento e certificação
- Minha conta
- Recursos para desenvolvedores
- Suporte ao cliente
- Calculadora de valor Red Hat
- Red Hat Ecosystem Catalog
- Encontre um parceiro
Experimente, compre, venda
Comunicação
- Contate o setor de vendas
- Fale com o Atendimento ao Cliente
- Contate o setor de treinamento
- Redes sociais
Sobre a Red Hat
A Red Hat é a líder mundial em soluções empresariais open source como Linux, nuvem, containers e Kubernetes. Fornecemos soluções robustas que facilitam o trabalho em diversas plataformas e ambientes, do datacenter principal até a borda da rede.
Selecione um idioma
Red Hat legal and privacy links
- Sobre a Red Hat
- Oportunidades de emprego
- Eventos
- Escritórios
- Fale com a Red Hat
- Blog da Red Hat
- Diversidade, equidade e inclusão
- Cool Stuff Store
- Red Hat Summit